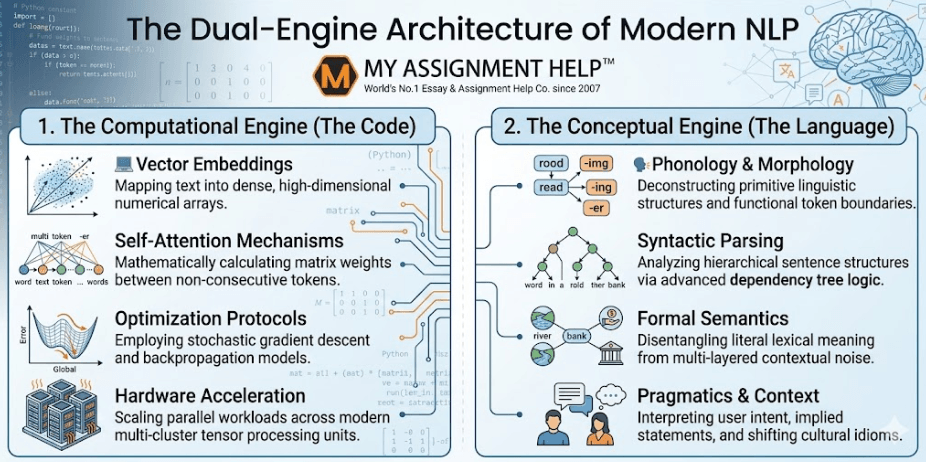
Ask any upper-year computer science student at a Canadian university what their most daunting coursework is this semester, and the answer is rarely standard database management or basic web development. Instead, a massive intellectual bottleneck has formed at the intersection of cognitive simulation and machine learning: Natural Language Processing (NLP). For digital platforms tracking cutting-edge developments, like TechBritish, analyzing this shift reveals a fundamental transformation in technical education. Historically, computational tracks and linguistic studies operated on completely parallel tracks. Today, the rapid maturation of Large Language Models (LLMs) and transformer architectures has forced an intellectual convergence. Tech undergraduates are no longer just software engineers building linear, deterministic paths; they are architectural pioneers exploring where rigid mathematics encounters the fluid, shifting boundaries of human dialect.
This convergence presents an immense operational challenge across Canadian educational ecosystems. Undergraduate and postgraduate cohorts from Vancouver to Toronto are discovering that the prerequisite math for modern language modeling is brutal. Curricula now demand simultaneous mastery of advanced neural structures, high-dimensional vector fields, and formal structural syntax. As Canadian computer science curricula grow more complex, students mastering these neural architectures frequently require advanced computer science assignment help to bridge the gap between abstract linear algebra and practical Python debugging. Stabilizing these foundational programming and matrix manipulation skills through targeted academic support has become a necessity for survival, allowing future technologists to free up the mental bandwidth required to solve the multi-layered structural puzzles underlying language engineering.
The Evolution of Language Engineering: From Rule-Based to Neural
To fully comprehend why this field has become an academic crucible, it is critical to trace its structural evolution. Early natural language systems relied heavily on symbolic, rule-based methodologies. Computer scientists diligently hardcoded explicit grammatical frameworks, writing thousands of nested logical statements to parse simple sentences. If an input sentence deviated even minutely from the pre-defined syntactic pathways, the entire compiler broke down. This absolute rigidness highlighted a major systemic vulnerability: human language cannot be effectively contained within deterministic, hardcoded constraints. Human communication thrives on contextual fluidity, evolving idioms, cultural nuances, and structural ellipsis.
The modern era bypassed this limitation by replacing explicit rule writing with probabilistic, data-driven machine learning models. The introduction of recurrent neural networks (RNNs) and Long Short-Term Memory (LSTM) blocks permitted architectures to process text sequentially, maintaining a form of computational memory across a string of words. However, sequential text processing introduces a systemic mathematical vulnerability known as the vanishing gradient problem, where contextual relationships over long paragraphs degrade exponentially. The true revolution materialized with the publication of the transformer architecture by Vaswani et al., which introduced the concept of the self-attention mechanism. Instead of processing text step-by-step, the transformer analyzes entire paragraphs simultaneously, computing contextual relationships between every single token in parallel. This mathematical architecture serves as the foundation for modern foundational language engines, turning language processing from a qualitative tracking problem into a high-dimensional vector space optimization exercise.
The Mathematical Framework Behind Tokenization and Vector Spaces
At its core computational layer, an NLP engine is entirely blind to alphabetical characters. Computers process numbers, meaning the primary phase of any linguistic workflow requires transforming textual expressions into explicit mathematical coordinates. This begins with advanced tokenization algorithms, such as Byte-Pair Encoding (BPE) or WordPiece. These mechanisms break strings into sub-word tokens, preventing the occurrence of out-of-vocabulary errors by isolating core morphological fragments.
Once tokenized, each discrete text unit is mapped into a dense vector space via an embedding matrix. These semantic embeddings convert textual elements into multi-dimensional coordinates, where words possessing conceptual commonality are placed close to one another within the vector field. For instance, the spatial distance between the vector coordinates for “matrix” and “determinant” is minimized, reflecting their technical relationship.
Mathematically, the directional similarity between two separate word vectors, designated as A and B, is routinely calculated using the cosine similarity formula:
$$\text{Cosine Similarity} = \frac{A \cdot B}{\|A\| \|B\|}$$
This structural metric tracks the cosine of the inner angle between the two multidimensional vectors. If the vectors are perfectly aligned, the similarity score equals 1, indicating absolute semantic alignment. Through these vector spaces, neural networks run mathematical transformations to deduce contextual relationship hierarchies, effectively converting abstract human prose into standardized linear algebra.
Bridging the Disconnect: Why Code Demands Linguistic Foundations
The hidden trap for many brilliant software engineering majors is assuming that building high-performing language technology is strictly an engineering optimization problem. Throwing massive raw computing power or deeper neural layers at unstructured datasets consistently fails when models face systemic data challenges and hallucination vulnerabilities. The true bottleneck stems from a clear disconnect between deterministic code structure and natural language patterns. This is precisely where the analytical methods of formal linguistic science become an mandatory blueprint for software developers. Without structural linguistic oversight, artificial intelligence models frequently struggle with structural ambiguity, coreference resolution, and semantic shifts.
To overcome these blind spots, students are realizing they must analyze how human syntax is systematically organized before they can train an algorithm to parse it. To build working models that survive rigorous university grading rubrics, engineering candidates are increasingly forced to review cross-disciplinary academic repositories, examining complex, peer-reviewed linguistics research topics to master the fundamentals of structural syntax, morphological shifts, and pragmatic variations. Analyzing these structured academic concepts allows developers to implement better data pre-processing rules, evaluate model performance with greater accuracy, and design cleaner prompt-tuning layers. By understanding the core mechanics of human dialect, software engineers can design semantic search patterns and retrieval-augmented generation (RAG) pipelines that accurately reflect human contextual boundaries rather than just processing statistical probabilities blindly.
Real-World Technical Implementations and Core Challenges
The practical execution of NLP systems inside the Canadian technology sector spans diverse industries, from fintech deployments in Toronto’s financial core to biomedical data analytics in Montreal’s research labs. Developers are actively engineering custom sentiment analysis platforms, automated conversational agents, and real-time document summarization pipelines. Yet, deploying these large-scale systems surfaces major architectural constraints:
- Data Sparsity & Bias: Models trained on general internet web scrapes routinely struggle when deployed within proprietary domains like corporate legal contracts or specialized medical diagnostics.
- Computational Cost: Fine-tuning models containing billions of parameters requires substantial GPU cluster infrastructure, pushing researchers to explore lighter frameworks like Low-Rank Adaptation (LoRA).
- Socio-Linguistic Nuances: Multi-dialect regions demand models that can seamlessly handle code-switching, structural idioms, and bilingual variations without dropping contextual processing capability.
These operational challenges ensure that the demand for hybrid professionals—engineers who are equally skilled in technical code compilation and linguistic structural analysis—continues to climb within the global technology sector.
Key Takeaways for Aspiring NLP Engineers
- Beyond Pure Code: Building top-tier language technology requires a strong grasp of both statistical machine learning and formal linguistic structures.
- Vector Transformations: Modern NLP transforms words into high-dimensional vector spaces, optimizing them through linear algebra and cosine similarity metrics.
- Structural Bridges: Academic pipelines are actively adapting, encouraging engineering cohorts to cross-reference linguistic data analytics with software engineering principles.
- Production Challenges: Real-world deployments must solve key bottlenecks around computing resource constraints, contextual data bias, and multi-dialect variations.
See also: How Technology Is Enhancing Workplace Efficiency
Frequently Asked Questions
Q1: What separates traditional rule-based text processing from modern neural NLP?
Traditional text systems relied entirely on hardcoded grammatical patterns and explicit if-else parameters, making them incredibly fragile. Modern neural NLP utilizes probabilistic models and self-attention mechanisms to analyze language context organically across multi-layered vector spaces.
Q2: Why do software developers need to study formal linguistics frameworks?
Pure statistical models often struggle with complex contextual nuances, structural sarcasm, and structural ambiguity. Studying formal linguistics provides developers with the structural insights needed to optimize training data parsing, design robust tokenizers, and mitigate model hallucinations.
Q3: How does cosine similarity function within language processing models?
Cosine similarity measures the inner angle between two multi-dimensional word vectors within a dense vector space. By calculating this metric, the system determines the semantic alignment between different words, scoring them between 0 and 1 based on contextual proximity.
About the Author
Dr. Aris Thorne is a Senior Academic Consultant and Content Strategist at MyAssignmentHelp, specializing in Computational Linguistics and Advanced Machine Learning Systems. With over a decade of research experience tracking computational shifts across the Canadian and global tech landscapes, Dr. Thorne guides undergraduate and postgraduate engineering students in mastering the architectural intersections of software engineering and natural language data models.
References and Academic Data Sources
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30, 5998-6008.
- Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Proceedings of the 2021 ACM FAccT Conference, 610-623.
- Canadian Institute for Advanced Research (CIFAR). (2025). The Evolution of Pan-Canadian Artificial Intelligence Strategies and the Growing Demand for Hybrid Technical Capital. AI Insights Quarterly Reports.